HttpProtocolNote
Doc site
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/
MIME 类型
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_Types
媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型)是一种标准,用来表示文档、文件或字节流的性质和格式。它在IETF RFC 6838中进行了定义和标准化。
警告: 浏览器通常使用 MIME 类型(而不是文件扩展名)来确定如何处理 URL,因此 Web 服务器在响应头中添加正确的 MIME 类型非常重要。如果配置不正确,浏览器可能会曲解文件内容,网站将无法正常工作,并且下载的文件也会被错误处理。
语法
通用结构
type/subtype
MIME 的组成结构非常简单;由类型与子类型两个字符串中间用'/'分隔而组成。不允许空格存在。type 表示可以被分多个子类的独立类别。subtype 表示细分后的每个类型。
MIME 类型对大小写不敏感,但是传统写法都是小写。
独立类型
text/plain
text/html
image/jpeg
image/png
audio/mpeg
audio/ogg
audio/*
video/mp4
application/*
application/json
application/javascript
application/ecmascript
application/octet-stream
…
Copy to Clipboard
独立类型表明了对文件的分类,可以是如下之一:
Multipart 类型
multipart/form-data
multipart/byteranges
Copy to Clipboard
Multipart 类型表示细分领域的文件类型的种类,经常对应不同的 MIME 类型。这是复合文件的一种表现方式。multipart/form-data 可用于联系 HTML Forms 和 POST 方法,
重要的 MIME 类型
application/octet-stream
这是应用程序文件的默认值。意思是 *未知的应用程序文件,*浏览器一般不会自动执行或询问执行。浏览器会像对待 设置了 HTTP 头Content-Disposition 值为 attachment 的文件一样来对待这类文件。
multipart/form-data
multipart/form-data 可用于HTML 表单从浏览器发送信息给服务器。作为多部分文档格式,它由边界线(一个由'--'开始的字符串)划分出的不同部分组成。每一部分有自己的实体,以及自己的 HTTP 请求头,Content-Disposition和 Content-Type 用于文件上传领域,最常用的 (Content-Length 因为边界线作为分隔符而被忽略)。
Content-Type: multipart/form-data; boundary=aBoundaryString
(other headers associated with the multipart document as a whole)
--aBoundaryString
Content-Disposition: form-data; name="myFile"; filename="img.jpg"
Content-Type: image/jpeg
(data)
--aBoundaryString
Content-Disposition: form-data; name="myField"
(data)
--aBoundaryString
(more subparts)
--aBoundaryString--
如下所示的表单:
<form action="http://localhost:8000/" method="post" enctype="multipart/form-data">
<input type="text" name="myTextField">
<input type="checkbox" name="myCheckBox">Check</input>
<input type="file" name="myFile">
<button>Send the file</button>
</form>
会发送这样的请求:
POST / HTTP/1.1
Host: localhost:8000
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Content-Type: multipart/form-data; boundary=---------------------------8721656041911415653955004498
Content-Length: 465
-----------------------------8721656041911415653955004498
Content-Disposition: form-data; name="myTextField"
Test
-----------------------------8721656041911415653955004498
Content-Disposition: form-data; name="myCheckBox"
on
-----------------------------8721656041911415653955004498
Content-Disposition: form-data; name="myFile"; filename="test.txt"
Content-Type: text/plain
Simple file.
-----------------------------8721656041911415653955004498--
对应的java类
// org.springframework.http.MediaType
static {
// Not using "valueOf' to avoid static init cost
ALL = new MediaType("*", "*");
APPLICATION_ATOM_XML = new MediaType("application", "atom+xml");
APPLICATION_CBOR = new MediaType("application", "cbor");
APPLICATION_FORM_URLENCODED = new MediaType("application", "x-www-form-urlencoded");
APPLICATION_GRAPHQL = new MediaType("application", "graphql+json");
APPLICATION_JSON = new MediaType("application", "json");
APPLICATION_JSON_UTF8 = new MediaType("application", "json", StandardCharsets.UTF_8);
APPLICATION_NDJSON = new MediaType("application", "x-ndjson");
APPLICATION_OCTET_STREAM = new MediaType("application", "octet-stream");
APPLICATION_PDF = new MediaType("application", "pdf");
APPLICATION_PROBLEM_JSON = new MediaType("application", "problem+json");
APPLICATION_PROBLEM_JSON_UTF8 = new MediaType("application", "problem+json", StandardCharsets.UTF_8);
APPLICATION_PROBLEM_XML = new MediaType("application", "problem+xml");
APPLICATION_RSS_XML = new MediaType("application", "rss+xml");
APPLICATION_STREAM_JSON = new MediaType("application", "stream+json");
APPLICATION_XHTML_XML = new MediaType("application", "xhtml+xml");
APPLICATION_XML = new MediaType("application", "xml");
IMAGE_GIF = new MediaType("image", "gif");
IMAGE_JPEG = new MediaType("image", "jpeg");
IMAGE_PNG = new MediaType("image", "png");
MULTIPART_FORM_DATA = new MediaType("multipart", "form-data");
MULTIPART_MIXED = new MediaType("multipart", "mixed");
MULTIPART_RELATED = new MediaType("multipart", "related");
TEXT_EVENT_STREAM = new MediaType("text", "event-stream");
TEXT_HTML = new MediaType("text", "html");
TEXT_MARKDOWN = new MediaType("text", "markdown");
TEXT_PLAIN = new MediaType("text", "plain");
TEXT_XML = new MediaType("text", "xml");
}
Http 概述
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Overview
HTTP 是无状态,有会话的
HTTP 是无状态的:在同一个连接中,两个执行成功的请求之间是没有关系的。这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。
而使用 HTTP 的头部扩展,HTTP Cookies 就可以解决这个问题。把 Cookies 添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
注意,HTTP 本质是无状态的,使用 Cookies 可以创建有状态的会话。
HTTP 身份验证
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Authentication
通用的 HTTP 认证框架
RFC 7235 定义了一个 HTTP 身份验证框架,服务器可以用来针对客户端的请求发送 challenge(质询信息),客户端则可以用来提供身份验证凭证。质询与应答的工作流程如下:服务器端向客户端返回 401(Unauthorized,未被授权的)状态码,并在 WWW-Authenticate 首部提供如何进行验证的信息,其中至少包含有一种质询方式。之后有意向证明自己身份的客户端可以在新的请求中添加 Authorization 首部字段进行验证,字段值为身份验证凭证信息。通常客户端会弹出一个密码框让用户填写,然后发送包含有恰当的 Authorization 首部的请求。
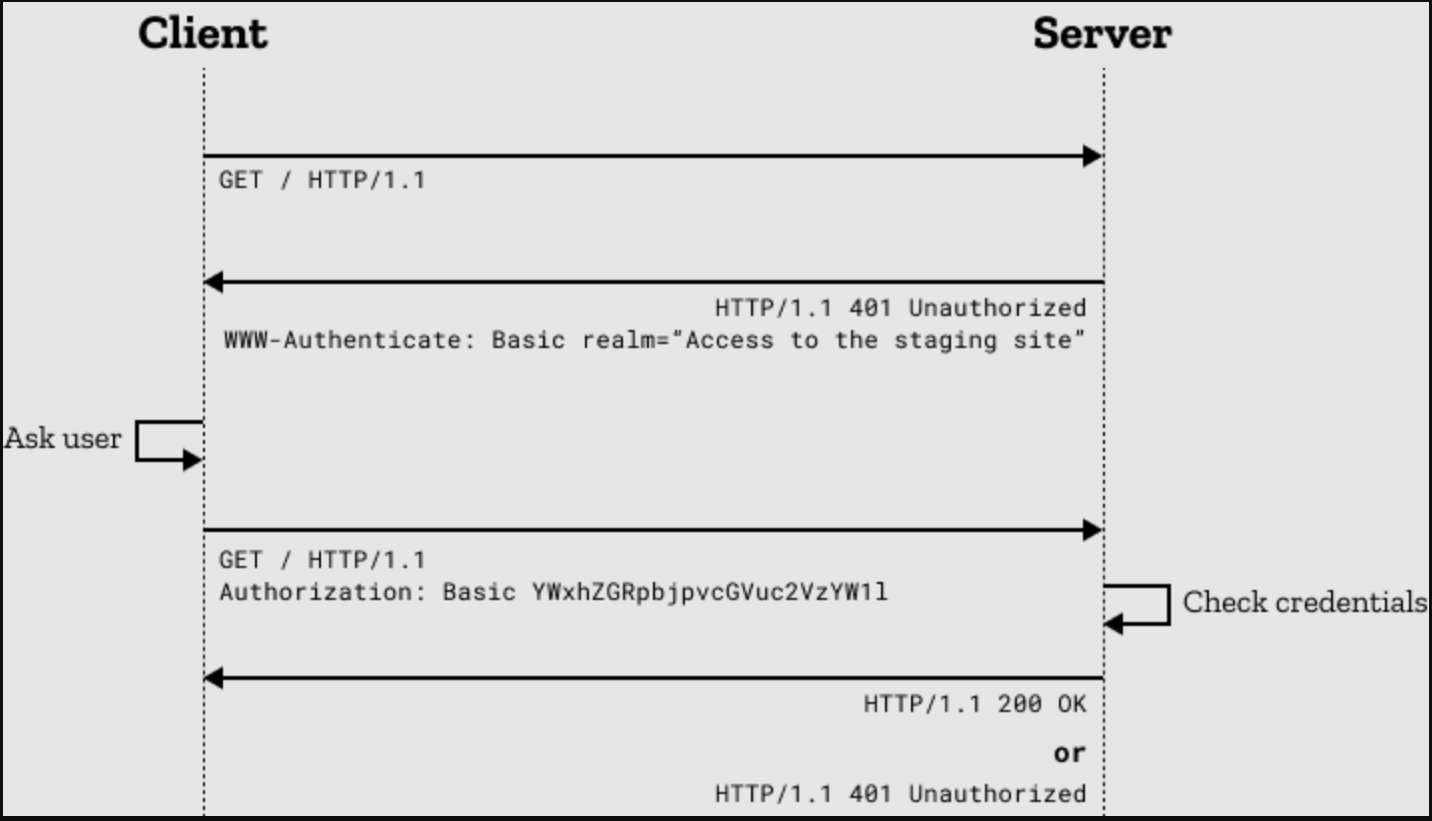
WWW-Authenticate 与 Proxy-Authenticate 首部
WWW-Authenticate 与 Proxy-Authenticate 响应消息首部指定了为获取资源访问权限而进行身份验证的方法。它们需要明确要进行验证的方案,这样希望进行授权的客户端就知道该如何提供凭证信息。这两个首部的语法形式如下:
WWW-Authenticate: <type> realm=<realm>
Proxy-Authenticate: <type> realm=<realm>
Copy to Clipboard
在这里,
Authorization 与 Proxy-Authorization 首部
Authorization 与 Proxy-Authorization 请求消息首部包含有用来向(代理)服务器证明用户代理身份的凭证。这里同样需要指明验证的类型,其后跟有凭证信息,该凭证信息可以被编码或者加密,取决于采用的是哪种验证方案。
Authorization: <type> <credentials>
Proxy-Authorization: <type> <credentials>
验证方案
通用 HTTP 身份验证框架可以被多个验证方案使用。不同的验证方案会在安全强度以及在客户端或服务器端软件中可获得的难易程度上有所不同。
最常见的验证方案是“基本验证方案”(“Basic”),该方案会在下面进行详细阐述。IANA 维护了一系列的验证方案,除此之外还有其他类型的验证方案由虚拟主机服务提供,例如 Amazon AWS。常见的验证方案包括:
- Basic (查看 RFC 7617,base64 编码凭证。详情请参阅下文.),
- Bearer (查看 RFC 6750,bearer 令牌通过 OAuth 2.0 保护资源),
- Digest (查看 RFC 7616,只有 md5 散列 在 Firefox 中支持,查看 bug 472823 用于 SHA 加密支持),
- HOBA (查看 RFC 7486(草案),HTTP Origin-Bound 认证,基于数字签名),
- Mutual (查看 draft-ietf-httpauth-mutual),
- AWS4-HMAC-SHA256 (查看 AWS docs).
HTTP Cookie
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
HTTP 的重定向
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Redirections
HTTP Headers
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
HTTP 消息头允许客户端和服务器通过 request和 response传递附加信息。一个请求头由名称(不区分大小写)后跟一个冒号 (:),冒号后跟具体的值(不带换行符)组成。该值前面的引导空白会被忽略。
自定专用消息头可通过’X-’ 前缀来添加;但是这种用法被 IETF 在 2012 年 6 月发布的 RFC6648 中明确弃用,原因是其会在非标准字段成为标准时造成不便;其他的消息头在 IANA 注册表 中列出,其原始内容在 RFC 4229 中定义。此外,IANA 还维护着被提议的新 HTTP 消息头注册表.
根据不同上下文,可将消息头分为:
- General headers: 同时适用于请求和响应消息,但与最终消息主体中传输的数据无关的消息头。
- Request headers: 包含更多有关要获取的资源或客户端本身信息的消息头。
- Response headers: 包含有关响应的补充信息,如其位置或服务器本身(名称和版本等)的消息头。
- Entity headers: 包含有关实体主体的更多信息,比如主体长 (Content-Length) 度或其 MIME 类型。
消息头也可以根据代理对其的处理方式分为:
Accept
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Accept
Accept 请求头用来告知(服务器)客户端可以处理的内容类型,这种内容类型用MIME 类型来表示。借助内容协商机制, 服务器可以从诸多备选项中选择一项进行应用,并使用 Content-Type 应答头通知客户端它的选择。
语法
Accept: <MIME_type>/<MIME_subtype>
Accept: <MIME_type>/*
Accept: */*
// Multiple types, weighted with the quality value syntax:
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8
Copy to Clipboard
指令
-
<MIME_type>/<MIME_subtype>单一精确的 MIME 类型,例如
text/html. -
<MIME_type>/*一类 MIME 类型,但是没有指明子类。
image/*可以用来指代image/png、image/svg、image/gif以及任何其他的图片类型。 -
*/*任意类型的 MIME 类型
-
;q=(q 因子权重)值代表优先顺序,用相对质量价值表示,又称作权重。
示例
Accept: text/html
Accept: image/*
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8
Accept-Charset
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Accept-Charset
Accept-Charset 请求头用来告知(服务器)客户端可以处理的字符集类型。借助内容协商机制,服务器可以从诸多备选项中选择一项进行应用,并使用Content-Type 应答头通知客户端它的选择。浏览器通常不会设置此项值,因为每种内容类型的默认值通常都是正确的,但是发送它会更有利于识别。
句法
Accept-Charset: <charset>
// Multiple types, weighted with the quality value syntax:
Accept-Charset: utf-8, iso-8859-1;q=0.5
Copy to Clipboard
指令
-
<charset>诸如
utf-8或iso-8859-15的字符集。 -
*在这个消息头中未提及的任意其他字符集;'*'用来表示通配符。 -
;q=(q-factor weighting)值代表优先顺序,用相对质量价值表示,又称为权重。
例子
Accept-Charset: iso-8859-1
Accept-Charset: utf-8, iso-8859-1;q=0.5
Accept-Charset: utf-8, iso-8859-1;q=0.5, *;q=0.1
Accept-Encoding
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Accept-Encoding
HTTP 请求头 Accept-Encoding 会将客户端能够理解的内容编码方式——通常是某种压缩算法——进行通知(给服务端)。通过内容协商的方式,服务端会选择一个客户端提议的方式,使用并在响应头 Content-Encoding 中通知客户端该选择。
即使客户端和服务器都支持相同的压缩算法,在 identity 指令可以被接受的情况下,服务器也可以选择对响应主体不进行压缩。导致这种情况出现的两种常见的情形是:
- 要发送的数据已经经过压缩,再次进行压缩不会导致被传输的数据量更小。一些图像格式的文件会存在这种情况;
- 服务器超载,无法承受压缩需求导致的计算开销。通常,如果服务器使用超过 80% 的计算能力,微软建议不要压缩。
只要 identity —— 表示不需要进行任何编码——没有被明确禁止使用(通过 identity;q=0 指令或是 *;q=0 而没有为 identity 明确指定权重值),则服务器禁止返回表示客户端错误的 406 Not Acceptable 响应。
语法
Accept-Encoding: gzip
Accept-Encoding: compress
Accept-Encoding: deflate
Accept-Encoding: br
Accept-Encoding: identity
Accept-Encoding: *
// Multiple algorithms, weighted with the quality value syntax:
Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5
Copy to Clipboard
指令
-
gzip表示采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式。
-
compress采用 Lempel-Ziv-Welch (LZW) 压缩算法。
-
deflate -
br表示采用 Brotli 算法的编码方式。
-
identity用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。
-
*匹配其他任意未在该请求头字段中列出的编码方式。假如该请求头字段不存在的话,这个值是默认值。它并不代表任意算法都支持,而仅仅表示算法之间无优先次序。
-
;q=(qvalues weighting)值代表优先顺序,用相对质量价值 表示,又称为权重。
Authorization
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Authorization
HTTP 协议中的 Authorization 请求消息头含有服务器用于验证用户代理身份的凭证,通常会在服务器返回401 Unauthorized 状态码以及WWW-Authenticate 消息头之后在后续请求中发送此消息头。
| Header type | Request header |
|---|---|
| Forbidden header name | no |
语法
Authorization: <type> <credentials>
Copy to Clipboard
指令
-
验证类型。常见的是 “基本验证(Basic)” 。其他类型包括:在 IANA 机构注册的验证方案AWS 服务器的验证方案 (
AWS4-HMAC-SHA256) -
如果使用“基本验证”方案,凭证通过如下步骤生成:用冒号将用户名和密码进行拼接(如:aladdin:opensesame)。将第一步生成的结果用 base64 方式编码 (YWxhZGRpbjpvcGVuc2VzYW1l)。备注: Base64 编码并不是一种加密方法或者 hashing 方法!这种方法的安全性与明文发送等同(base64 可以逆向解码)。“基本验证”方案需要与 HTTPS 协议配合使用。
示例
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
Content-Disposition
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition
在常规的 HTTP 应答中,Content-Disposition 响应头指示回复的内容该以何种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地。
在 multipart/form-data 类型的应答消息体中,Content-Disposition 消息头可以被用在 multipart 消息体的子部分中,用来给出其对应字段的相关信息。各个子部分由在Content-Type 中定义的分隔符分隔。用在消息体自身则无实际意义。
语法
作为消息主体中的消息头
在 HTTP 场景中,第一个参数或者是 inline(默认值,表示回复中的消息体会以页面的一部分或者整个页面的形式展示),或者是 attachment(意味着消息体应该被下载到本地;大多数浏览器会呈现一个“保存为”的对话框,将 filename 的值预填为下载后的文件名,假如它存在的话)。
Content-Disposition: inline
Content-Disposition: attachment
Content-Disposition: attachment; filename="filename.jpg"
作为 multipart body 中的消息头
在 HTTP 场景中。第一个参数总是固定不变的 form-data;附加的参数不区分大小写,并且拥有参数值,参数名与参数值用等号 ('=') 连接,参数值用双引号括起来。参数之间用分号 (';') 分隔。
Content-Disposition: form-data
Content-Disposition: form-data; name="fieldName"
Content-Disposition: form-data; name="fieldName"; filename="filename.jpg"
指令
-
name后面是一个表单字段名的字符串,每一个字段名会对应一个子部分。在同一个字段名对应多个文件的情况下(例如,带有
multiple属性的<input type=file>元素),则多个子部分共用同一个字段名。如果 name 参数的值为'_charset_',意味着这个子部分表示的不是一个 HTML 字段,而是在未明确指定字符集信息的情况下各部分使用的默认字符集。 -
filename后面是要传送的文件的初始名称的字符串。这个参数总是可选的,而且不能盲目使用:路径信息必须舍掉,同时要进行一定的转换以符合服务器文件系统规则。这个参数主要用来提供展示性信息。当与
Content-Disposition: attachment一同使用的时候,它被用作"保存为"对话框中呈现给用户的默认文件名。 -
filename*
“filename” 和 “filename*” 两个参数的唯一区别在于,“filename*” 采用了 RFC 5987 中规定的编码方式。当 “filename” 和 “filename*” 同时出现的时候,应该优先采用 “filename*”,假如二者都支持的话。
filename*主要解决,下载下来的文件名乱码的问题
http://www.javashuo.com/article/p-mxwxymam-dg.html
http://mirrors.nju.edu.cn/rfc/rfc5987.html
RFC 5987 - Character Set and Language Encoding for Hypertext Transfer Protocol (HTTP) Header Field Parameters 的文档,顿时拨开迷雾见青天:
By default, message header field parameters in HTTP ([RFC2616]) messages cannot carry characters outside the ISO-8859-1 character set. RFC 2231 defines an encoding mechanism for use in MIME headers. This document specifies an encoding suitable for use in HTTP header fields that is compatible with a profile of the encoding defined in RFC 2231.
文中的Guidelines for Usage in HTTP Header Field Definitions给出了一个通用表达式:
foo-header = "foo" LWSP ":" LWSP token ";" LWSP title-param
title-param = "title" LWSP "=" LWSP value
/ "title*" LWSP "=" LWSP ext-value
ext-value = charset "'" [ language ] "'" value-chars
charset = "UTF-8" / "ISO-8859-1" / mime-charset
value-chars = *( pct-encoded / attr-char )
将前面非法的Content-Disposition转化过来就是:
Content-Disposition : attachment; filename* = UTF-8''%E6%96%87%E4%BB%B6.txt
这里对“文件.txt”进行了编码:先进行UTF-8编码,再进行pct-encoded编码。其实就是URL_ENCODE的过程。。。
java的写法如下:
String percentEncodedFileName = percentEncode(realFileName);
StringBuilder contentDispositionValue = new StringBuilder();
contentDispositionValue.append("attachment; filename=")
.append(percentEncodedFileName)
.append(";")
.append("filename*=")
.append("utf-8''")
.append(percentEncodedFileName);
response.addHeader("Access-Control-Expose-Headers", "Content-Disposition,download-filename");
response.setHeader("Content-disposition", contentDispositionValue.toString());
response.setHeader("download-filename", percentEncodedFileName);
//
public static String percentEncode(String s) throws UnsupportedEncodingException
{
String encode = URLEncoder.encode(s, StandardCharsets.UTF_8.toString());
return encode.replaceAll("\\+", "%20");
}
示例
以下是一则可以触发"保存为"对话框的服务器应答:
200 OK
Content-Type: text/html; charset=utf-8
Content-Disposition: attachment; filename="cool.html"
Content-Length: 22
<HTML>Save me!</HTML>
Copy to Clipboard
这个简单的 HTML 文件会被下载到本地而不是在浏览器中展示。大多数浏览器默认会建议将 cool.html 作为文件名。
以下是一个 HTML 表单的示例,展示了在 multipart/form-data 格式的报文中使用Content-Disposition 消息头的情况:
POST /test.html HTTP/1.1
Host: example.org
Content-Type: multipart/form-data;boundary="boundary"
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2"; filename="example.txt"
value2
--boundary--
Content-Encoding
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Encoding
实体消息首部 (en-US) Content-Encoding 列出了对当前实体消息(消息荷载)应用的任何编码类型,以及编码的顺序。它让接收者知道需要以何种顺序解码该实体消息才能获得原始荷载格式。Content-Encoding 主要用于在不丢失原媒体类型内容的情况下压缩消息数据。
请注意原始媒体/内容的类型通过 Content-Type 首部给出,而 Content-Encoding 应用于数据的表示,或“编码形式”。如果原始媒体以某种方式编码(例如 zip 文件),则该信息不应该被包含在 Content-Encoding 首部内。
一般建议服务器应对数据尽可能地进行压缩,并在适当情况下对内容进行编码。对一种压缩过的媒体类型如 zip 或 jpeg 进行额外的压缩并不合适,因为这反而有可能会使荷载增大。
Content-Type
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Type
Content-Type 实体头部用于指示资源的 MIME 类型 media type 。
在响应中,Content-Type 标头告诉客户端实际返回的内容的内容类型。
句法
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
Copy to Clipboard
指令
-
media-type资源或数据的 MIME type 。
-
charset
字符编码标准。
-
boundary
对于多部分实体,boundary 是必需的,其包括来自一组字符的 1 到 70 个字符,已知通过电子邮件网关是非常健壮的,而不是以空白结尾。它用于封装消息的多个部分的边界。
例子
Content-Type 在 HTML 表单中
在通过 HTML form 提交生成的POST请求中,请求头的 Content-Type 由``元素上的 enctype 属性指定
<form action="/" method="post" enctype="multipart/form-data">
<input type="text" name="description" value="some text">
<input type="file" name="myFile">
<button type="submit">Submit</button>
</form>
Copy to Clipboard
请求头看起来像这样(在这里省略了一些 headers):
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: multipart/form-data; boundary=---------------------------974767299852498929531610575
---------------------------974767299852498929531610575
Content-Disposition: form-data; name="description"
some text
---------------------------974767299852498929531610575
Content-Disposition: form-data; name="myFile"; filename="foo.txt"
Content-Type: text/plain
(content of the uploaded file foo.txt)
---------------------------974767299852498929531610575
Location
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Location
Location 首部指定的是需要将页面重新定向至的地址。一般在响应码为 3xx 的响应中才会有意义。
发送新请求,获取 Location 指向的新页面所采用的方法与初始请求使用的方法以及重定向的类型相关:
303(See Also) 始终引致请求使用GET方法,而,而307(Temporary Redirect) 和308(Permanent Redirect) 则不转变初始请求中的所使用的方法;301(Permanent Redirect) 和302(Found) 在大多数情况下不会转变初始请求中的方法,不过一些比较早的用户代理可能会引发方法的变更(所以你基本上不知道这一点)。
状态码为上述之一的所有响应都会带有一个 Location 首部。
除了重定向响应之外,状态码为 201 (Created) 的消息也会带有 Location 首部。它指向的是新创建的资源的地址。
Location 与 Content-Location是不同的,前者(Location )指定的是一个重定向请求的目的地址(或者新创建的文件的 URL),而后者( Content-Location)指向的是经过内容协商后的资源的直接地址,不需要进行进一步的内容协商。Location 对应的是响应,而 Content-Location 对应的是要返回的实体。
X-Forwarded-For
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/X-Forwarded-For
X-Forwarded-For (XFF) 在客户端访问服务器的过程中如果需要经过 HTTP 代理或者负载均衡服务器,可以被用来获取最初发起请求的客户端的 IP 地址,这个消息首部成为事实上的标准。在消息流从客户端流向服务器的过程中被拦截的情况下,服务器端的访问日志只能记录代理服务器或者负载均衡服务器的 IP 地址。如果想要获得最初发起请求的客户端的 IP 地址的话,那么 X-Forwarded-For 就派上了用场。
语法
X-Forwarded-For: <client>, <proxy1>, <proxy2>
Copy to Clipboard
指令
-
客户端的 IP 地址。
-
, 如果一个请求经过了多个代理服务器,那么每一个代理服务器的 IP 地址都会被依次记录在内。也就是说,最右端的 IP 地址表示最近通过的代理服务器,而最左端的 IP 地址表示最初发起请求的客户端的 IP 地址。
示例
X-Forwarded-For: 2001:db8:85a3:8d3:1319:8a2e:370:7348
X-Forwarded-For: 203.0.113.195
X-Forwarded-For: 203.0.113.195, 70.41.3.18, 150.172.238.178
实例数据
上传的请求头和请求体
POST /common/upload HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Authorization: Bearer eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6ImVhZjcyNDhhLWRjOTAtNDZjZS05ZTk1LTBkOTQyNjhhYmIwZSJ9.BHesq7sn_gPhRH77q0z3HRiJm0-Dl43K_zgMrFam_zk4PfVisrX1vHmJcE40VXReRDWq_Vu3K2CRhSUzXb5Z2g
Connection: keep-alive
Content-Length: 42192
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryl5z4xQZ5EquIMrzq
Host: 221.181.222.135:8082
Origin: http://221.181.222.135:8086
Referer: http://221.181.222.135:8086/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.42
body如下:
------WebKitFormBoundaryl5z4xQZ5EquIMrzq
Content-Disposition: form-data; name="file"; filename="OIP-C.jpg"
Content-Type: image/jpeg
------WebKitFormBoundaryl5z4xQZ5EquIMrzq--
下载用到的知识
Access-Control-Expose-Headers
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Access-Control-Expose-Headers
响应首部 Access-Control-Expose-Headers 列出了哪些首部可以作为响应的一部分暴露给外部。
默认情况下,只有七种 simple response headers(简单响应首部)可以暴露给外部:
如果想要让客户端可以访问到其他的首部信息,可以将它们在 Access-Control-Expose-Headers 里面列出来。
语法
Access-Control-Expose-Headers: <header-name>, <header-name>, ...
Copy to Clipboard
指令
-
包含 0 个或多个除 simple response headers(简单响应首部)之外的首部名称列表,可以暴露给外部,供页面资源使用。
示例
想要暴露一个非简单响应首部,可以这样指定:
Access-Control-Expose-Headers: Content-Length
Copy to Clipboard
想要额外暴露自定义的首部,例如 X-Kuma-Revision,可以指定多个,用逗号隔开:
Access-Control-Expose-Headers: Content-Length, X-Kuma-Revision
下载,添加header的代码如下:
public static void setAttachmentResponseHeader(HttpServletResponse response, String realFileName) throws UnsupportedEncodingException
{
String percentEncodedFileName = percentEncode(realFileName);
StringBuilder contentDispositionValue = new StringBuilder();
contentDispositionValue.append("attachment; filename=")
.append(percentEncodedFileName)
.append(";")
.append("filename*=")
.append("utf-8''")
.append(percentEncodedFileName);
response.addHeader("Access-Control-Expose-Headers", "Content-Disposition,download-filename");
response.setHeader("Content-disposition", contentDispositionValue.toString());
response.setHeader("download-filename", percentEncodedFileName);
}
跨域涉及到知识
OPTIONS
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/OPTIONS
HTTP 的 OPTIONS 方法 用于获取目的资源所支持的通信选项。客户端可以对特定的 URL 使用 OPTIONS 方法,也可以对整站(通过将 URL 设置为“*”)使用该方法。
语法
OPTIONS /index.html HTTP/1.1
OPTIONS * HTTP/1.1
Copy to Clipboard
示例
检测服务器所支持的请求方法
可以使用 OPTIONS 方法对服务器发起请求,以检测服务器支持哪些 HTTP 方法:
curl -X OPTIONS http://example.org -i
Copy to Clipboard
响应报文包含一个 Allow 首部字段,该字段的值表明了服务器支持的所有 HTTP 方法:
HTTP/1.1 200 OK
Allow: OPTIONS, GET, HEAD, POST
Cache-Control: max-age=604800
Date: Thu, 13 Oct 2016 11:45:00 GMT
Expires: Thu, 20 Oct 2016 11:45:00 GMT
Server: EOS (lax004/2813)
x-ec-custom-error: 1
Content-Length: 0
Copy to Clipboard
CORS 中的预检请求
在 CORS 中,可以使用 OPTIONS 方法发起一个预检请求,以检测实际请求是否可以被服务器所接受。预检请求报文中的 Access-Control-Request-Method 首部字段告知服务器实际请求所使用的 HTTP 方法;Access-Control-Request-Headers 首部字段告知服务器实际请求所携带的自定义首部字段。服务器基于从预检请求获得的信息来判断,是否接受接下来的实际请求。
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.other
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: http://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
Copy to Clipboard
服务器所返回的 Access-Control-Allow-Methods 首部字段将所有允许的请求方法告知客户端。该首部字段与 Allow 类似,但只能用于涉及到 CORS 的场景中。
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
HEAD
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/HEAD
HTTP HEAD 方法 请求资源的头部信息,并且这些头部与 HTTP GET 方法请求时返回的一致。该请求方法的一个使用场景是在下载一个大文件前先获取其大小再决定是否要下载,以此可以节约带宽资源。
HEAD 方法的响应不应包含响应正文。即使包含了正文也必须忽略掉。虽然描述正文信息的 entity headers, 例如 Content-Length 可能会包含在响应中,但它们并不是用来描述 HEAD 响应本身的,而是用来描述同样情况下的 GET 请求应该返回的响应。
语法
HEAD /index.html
Access-Control-Allow-Credentials
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 响应头用于在请求要求包含 credentials(Request.credentials 的值为 include)时,告知浏览器是否可以将对请求的响应暴露给前端 JavaScript 代码。
Credentials 可以是 cookies、authorization headers 或 TLS client certificates。
当作为对预检请求的响应的一部分时,这能表示是否真正的请求可以使用 credentials。
语法
Access-Control-Allow-Credentials: true
Copy to Clipboard
指令
-
true
这个头的唯一有效值(区分大小写)。如果不需要 credentials,相比将其设为 false,请直接忽视这个头。
例子
允许 credentials:
Access-Control-Allow-Credentials: true
使用带 credentials 的 XHR:
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://example.com/', true);
xhr.withCredentials = true;
xhr.send(null);
Copy to Clipboard
使用带 credentials 的 Fetch:
fetch(url, {
credentials: 'include'
})
Access-Control-Allow-Origin
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Access-Control-Allow-Origin
Access-Control-Allow-Origin 响应标头指定了该响应的资源是否被允许与给定的来源(origin)共享。
指令
-
*对于不包含凭据的请求,服务器会以“
*”作为通配符,从而允许任意来源的请求代码都具有访问资源的权限。尝试使用通配符来响应包含凭据的请求会导致错误。 -
<origin>指定一个来源(只能指定一个)。如果服务器支持多个来源的客户端,其必须以与指定客户端匹配的来源来响应请求。
示例
一个告诉浏览器允许任何来源的代码访问资源的响应将包括以下内容:
Access-Control-Allow-Origin: *
Copy to Clipboard
如需允许 https://developer.mozilla.org 源访问资源,响应应包含以下内容:
Access-Control-Allow-Origin: https://developer.mozilla.org
Copy to Clipboard
将可能的 Access-Control-Allow-Origin 值限制在一组允许的源,需要服务器端的代码检查 Origin 请求标头的值,将其与允许的来源列表进行比较,如果 Origin 值在列表中,将 Access-Control-Allow-Origin 设置为与 Origin 标头相同的值。
CORS 和缓存
如果服务器未使用通配符“*”,而是指定了明确的来源,那么为了向客户端表明服务器的返回会根据 Origin 请求标头而有所不同,必须在 Vary 响应标头中包含 Origin。
Access-Control-Allow-Origin: https://developer.mozilla.org
Vary: Origin
跨域与CORS
跨域是一种浏览器同源安全策略,即浏览器单方面限制脚本的跨域访问
认识跨域
很多人误认为资源跨域时无法请求,实际上,通常情况下请求是可以正常发起的(注意,部分浏览器存在特例),后端也正常进行了处理,只是在返回时被浏览器拦截,导致响应内容不可使用。可以论证这一点的著名案例就是CSRF跨站攻击。
此外,我们平常所说的跨域实际上都是在讨论浏览器行为,包括各种WebView容器等(其中,以XmlHttpRequest 的使用为主)。由于JavaScript 运行在浏览器之上,所以 Ajax的跨域成为“痛点”。
实际上,不仅不同站点间的访问存在跨域问题,同站点间的访问可能也会遇到跨域问题,只要请求的URL与所在页面的URL首部不同即产生跨域,例如:
◎ 在http://a.baidu.com下访问https://a.baidu.com资源会形成协议跨域。
◎ 在a.baidu.com下访问b.baidu.com资源会形成主机跨域。
◎ 在a.baidu.com:80下访问a.baidu.com:8080资源会形成端口跨域
从协议部分开始到端口部分结束,只要与请求URL不同即被认为跨域,域名与域名对应的IP也不能幸免。
跨域可以通过nginx转发 或者 cors处理
实现跨域之CORS
CORS(Cross-Origin Resource Sharing)的规范中有一组新增的HTTP首部字段,允许服务器声明其提供的资源允许哪些站点跨域使用。
通常情况下,跨域请求即便在不被支持的情况下,服务器也会接收并进行处理,在CORS的规范中则避免了这个问题。
浏览器首先会发起一个请求方法为OPTIONS 的预检请求,用于确认服务器是否允许跨域,只有在得到许可后才会发出实际请求。此外,预检请求还允许服务器通知浏览器跨域携带身份凭证(如cookie)。
CORS新增的HTTP首部字段由服务器控制,下面我们来看看常用的几个首部字段
Access-Control-Allow-Origin
允许取值为
如果设置了具体的站点信息,则响应头中的Vary字段还需要携带Origin属性,因为服务器对不同的域会返回不同的内容:
Access-Control-Allow-Origin: https://developer.mozilla.org
Vary: Origin
Access-Control-Allow-Methods字段仅在预检请求的响应中指定有效,用于表明服务器允许跨域的HTTP方法,多个方法之间用逗号隔开。
Access-Control-Allow-Headers 字段仅在预检请求的响应中指定有效,用于表明服务器允许携带的首部字段。多个首部字段之间用逗号隔开。
Access-Control-Max-Age 字段用于指明本次预检请求的有效期,单位为秒。在有效期内,预检请求不需要再次发起。
当Access-Control-Allow-Credentials字段取值为true时,浏览器会在接下来的真实请求中携带用户凭证信息(cookie等),服务器也可以使用Set-Cookie向用户浏览器写入新的cookie。注意,使用Access-Control-Allow-Credentials时,Access-Control-Allow-Origin不应该设置为*。
总体来说,CORS 是一种更安全的官方跨域解决方案,它依赖于浏览器和后端,即当需要用CORS来解决跨域问题时,只需要后端做出支持即可。前端在使用这些域时,基本等同于访问同源站点资源。注意,CORS不支持IE8以下版本的浏览器。
在使用CORS时,通常有以下三种访问控制场景。
1.简单请求
在CORS中,并非所有的跨域访问都会触发预检请求。例如,不携带自定义请求头信息的GET 请求、HEAD请求,以及Content-Type
为application/x-www-form-urlencoded、multipart/form-data或text/plain的POST请求,这类请求被称为简单请求。
浏览器在发起请求时,会在请求头中自动添加一个 Origin 属性,值为当前页面的 URL 首部。当服务器返回响应时,若存在跨域访问控制属性,则浏览器会通过这些属性判断本次请求是否被允许,如果允许,则跨域成功(正常接收数据)
HTTP/1.1 200 OK
...
...
Access-Control-Allow-Origin: https://developer.mozilla.org
这种跨域请求非常简单,只需后端在返回的响应头中添加 Access-Control-Allow-Origin 字段并填入允许跨域访问的站点即可。
2.预检请求
预检请求不同于简单请求,它会发送一个 OPTIONS 请求到目标站点,以查明该请求是否安全,防止请求对目标站点的数据造成破坏。若是请求以 GET、HEAD、POST 以外的方法发起;或者使用POST方法,但请求数据为application/x-www-form-urlencoded、multipart/form-data和text/plain以外的数据类型;再或者,使用了自定义请求头,则都会被当成预检请求类型处理。
3.带凭证的请求
带凭证的请求,顾名思义,就是携带了用户cookie等信息的请求。
在使用XMLHttpRequest时,指定了withCredentials为true。浏览器在实际发出请求时,将同时向服务器发送 cookie,并期待在服务器返回的响应信息中指明 Access-Control-AllowCredentials为true,否则浏览器会拦截,并抛出错误。
启用Spring Security的CORS支持
事实上,Spring Security对CORS提供了非常好的支持,只需在配置器中启用CORS支持,并编写一个CORS配置源即可
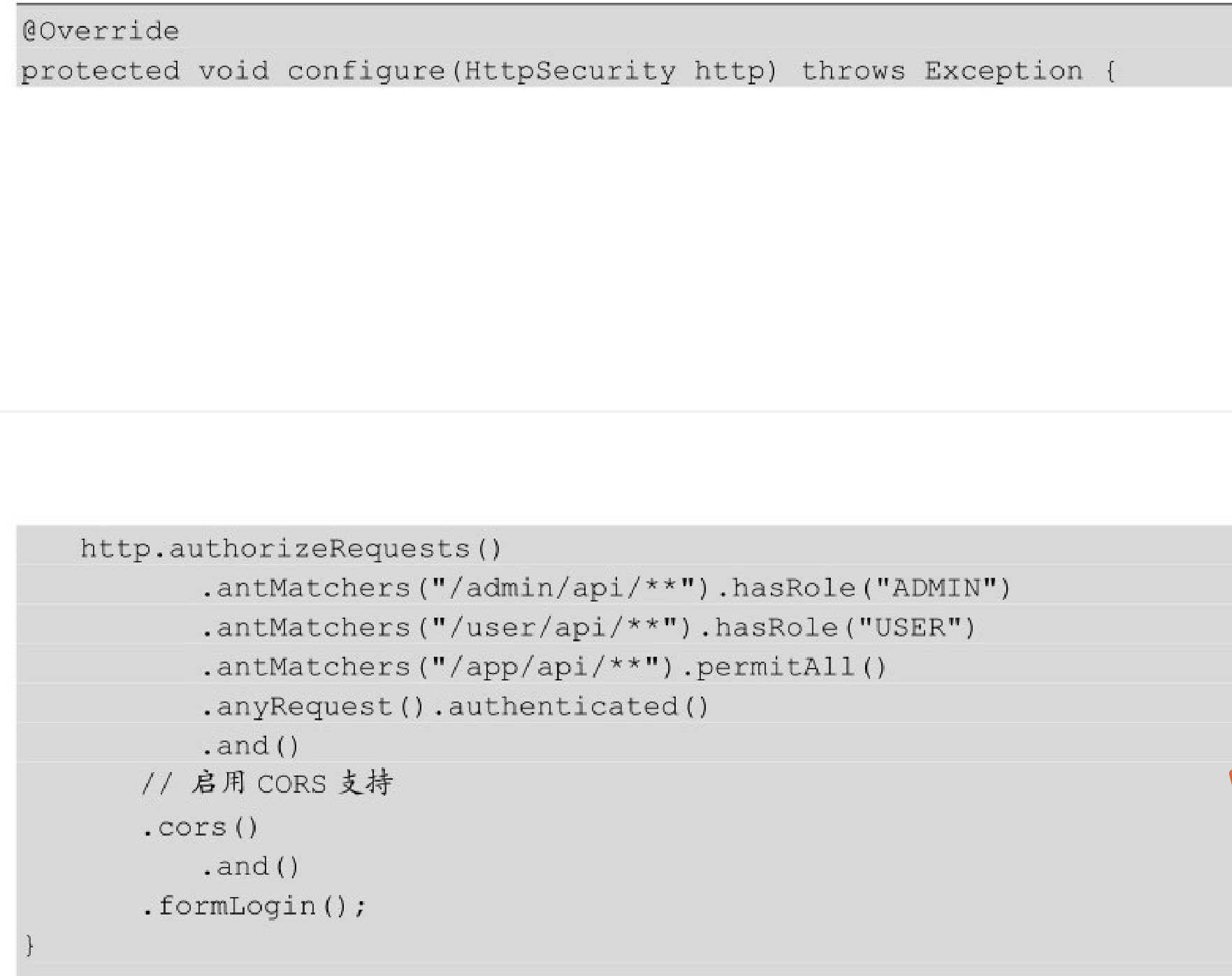

实现原理
有一个corsFilter
public class CorsFilter extends OncePerRequestFilter {
调用链如下:
CorsFilter#doFilterInternal----->DefaultCorsProcessor#processRequest---->DefaultCorsProcessor#handleInternal
// DefaultCorsProcessor#handleInternal
protected boolean handleInternal(ServerHttpRequest request, ServerHttpResponse response,
CorsConfiguration config, boolean preFlightRequest) throws IOException {
String requestOrigin = request.getHeaders().getOrigin();
// request中被允许的域
String allowOrigin = checkOrigin(config, requestOrigin);
HttpHeaders responseHeaders = response.getHeaders();
if (allowOrigin == null) {
logger.debug("Reject: '" + requestOrigin + "' origin is not allowed");
rejectRequest(response);
return false;
}
HttpMethod requestMethod = getMethodToUse(request, preFlightRequest);
// request中被允许的方法
List<HttpMethod> allowMethods = checkMethods(config, requestMethod);
if (allowMethods == null) {
logger.debug("Reject: HTTP '" + requestMethod + "' is not allowed");
rejectRequest(response);
return false;
}
List<String> requestHeaders = getHeadersToUse(request, preFlightRequest);
// request中被允许的头字段
List<String> allowHeaders = checkHeaders(config, requestHeaders);
if (preFlightRequest && allowHeaders == null) {
logger.debug("Reject: headers '" + requestHeaders + "' are not allowed");
rejectRequest(response);
return false;
}
responseHeaders.setAccessControlAllowOrigin(allowOrigin);
if (preFlightRequest) {
responseHeaders.setAccessControlAllowMethods(allowMethods);
}
if (preFlightRequest && !allowHeaders.isEmpty()) {
responseHeaders.setAccessControlAllowHeaders(allowHeaders);
}
if (!CollectionUtils.isEmpty(config.getExposedHeaders())) {
responseHeaders.setAccessControlExposeHeaders(config.getExposedHeaders());
}
if (Boolean.TRUE.equals(config.getAllowCredentials())) {
responseHeaders.setAccessControlAllowCredentials(true);
}
if (preFlightRequest && config.getMaxAge() != null) {
responseHeaders.setAccessControlMaxAge(config.getMaxAge());
}
response.flush();
return true;
}
CharSet
java.nio.charset.StandardCharsets#UTF_8
// 根据字符串,获取枚举值 Charset.forName("UTF-8")
Charset charset = Charset.forName("UTF-8");
System.out.println(charset);
// 根据charset枚举值,获取字符串
String s = StandardCharsets.UTF_8.displayName();
String beijingZone = URLEncoder.encode("GMT+8", s);
System.out.println(beijingZone); // GMT%2B8 这下知道mysql连接中时区,需要写成这样了吧,就是因为,需要写成html application/x-www-form-urlencoded MIME format
converting a String to the application/x-www-form-urlencoded MIME format—URLEncoder
https://docs.oracle.com/javase/8/docs/api/java/net/URLEncoder.html
public class URLEncoder
extends Object
Utility class for HTML form encoding. This class contains static methods for converting a String to the application/x-www-form-urlencoded MIME format. For more information about HTML form encoding, consult the HTML specification.
When encoding a String, the following rules apply:
- The alphanumeric characters “
a” through “z”, “A” through “Z” and “0” through “9” remain the same. - The special characters “
.”, “-”, “*”, and “_” remain the same. - The space character " " is converted into a plus sign “
+”. - All other characters are unsafe and are first converted into one or more bytes using some encoding scheme. Then each byte is represented by the 3-character string “
%xy”, where xy is the two-digit hexadecimal representation of the byte. The recommended encoding scheme to use is UTF-8. However, for compatibility reasons, if an encoding is not specified, then the default encoding of the platform is used.
For example using UTF-8 as the encoding scheme the string “The string ü@foo-bar” would get converted to “The+string+%C3%BC%40foo-bar” because in UTF-8 the character ü is encoded as two bytes C3 (hex) and BC (hex), and the character @ is encoded as one byte 40 (hex).
| Modifier and Type | Method and Description |
|---|---|
static String |
encode(String s, String enc)Translates a string into application/x-www-form-urlencoded format using a specific encoding scheme. |
// 根据charset枚举值,获取字符串
String s = StandardCharsets.UTF_8.displayName();
String beijingZone = URLEncoder.encode("GMT+8", s);
System.out.println(beijingZone); // GMT%2B8 这下知道mysql连接中时区,需要写成这样了吧,就是因为,需要写成html application/x-www-form-urlencoded MIME format
下面,其实URLEncoder编码,其实使用的就是百分号编码Percent-encoding。参考如下:
https://developer.mozilla.org/en-US/docs/Glossary/percent-encoding
Percent-encoding is a mechanism to encode 8-bit characters that have specific meaning in the context of URLs. It is sometimes called URL encoding. The encoding consists of substitution: A ‘%’ followed by the hexadecimal representation of the ASCII value of the replace character.
Special characters needing encoding are: ‘:’, ‘/’, ‘?’, ‘#’, ‘[’, ‘]’, ‘@’, ‘!’, ‘$’, ‘&’, “'”, ‘(’, ‘)’, ‘*’, ‘+’, ‘,’, ‘;’, ‘=’, as well as ‘%’ itself. Other characters don’t need to be encoded, though they could.
| Character | Encoding |
|---|---|
':' |
%3A |
'/' |
%2F |
'?' |
%3F |
'#' |
%23 |
'[' |
%5B |
']' |
%5D |
'@' |
%40 |
'!' |
%21 |
'$' |
%24 |
'&' |
%26 |
"'" |
%27 |
'(' |
%28 |
')' |
%29 |
'*' |
%2A |
'+' |
%2B |
',' |
%2C |
';' |
%3B |
'=' |
%3D |
'%' |
%25 |
' ' |
%20 or + |
Depending on the context, the character ’ ’ is translated to a ‘+’ (like in the percent-encoding version used in an application/x-www-form-urlencoded message), or in ‘%20’ like on URLs.
注意,上面的空格字符,被编码后,有2种可能,一种是%20 ,一种是+。
当空格在作为URL的时候,编码是转为 %20
当空格作为 post提交(application/x-www-form-urlencoded)替换为 +
而URLEncoder的encode方法,只会将空格,编码成+,所以,当我们需要得到一个URL时,我们还需要将+,替换为%20。
如下:
String str = "a b";
String encode = URLEncoder.encode(str, StandardCharsets.UTF_8.displayName());
System.out.println(encode);
System.out.println("-----------------");
String s = encode.replaceAll("\\+", "%20");
System.out.println(s);
输出:
a+b
-----------------
a%20b
UrlBuilder
针对URL的编码和解码,除了Jdk提供的 URLEncoder,HuTool包也提供了一个类似的工具类:UrlBuilder。版本需要在5.3.3以上。
按照Uniform Resource Identifier的标准定义,URL的结构如下:
[scheme:]scheme-specific-part[#fragment]
[scheme:][//authority][path][?query][#fragment]
[scheme:][//host:port][path][?query][#fragment]
按照这个格式,UrlBuilder将URL分成scheme、host、port、path、query、fragment部分,其中path和query较为复杂,又使用UrlPath和UrlQuery分别封装。
生成URL
import cn.hutool.core.net.url.UrlBuilder;
public class TestUrlBuilder {
public static void main(String[] args) {
String url = UrlBuilder.create().setScheme("http").setHost("192.168.0.236")
.addPath("/aa").addPath("bb")
.addQuery("name", "zhangsan")
.addQuery("age", "15")
.build();
System.out.println(url); // http://192.168.0.236/aa/bb?name=zhangsan&age=15
String specialCharacterUrl = UrlBuilder.create().setScheme("http").setHost("192.168.0.236")
.addPath("/aa").addPath("bb")
.addQuery("name", "zhang san+lisi")
.addQuery("age", "15")
.build();
System.out.println(specialCharacterUrl); // http://192.168.0.236/aa/bb?name=zhang%20san%2Blisi&age=15
}
}
解析URL
String encodingUrl = "http://192.168.0.236/aa/bb?name=zhang%20san%2Blisi&age=15";
UrlBuilder urlBuilder = UrlBuilder.ofHttp(encodingUrl, StandardCharsets.UTF_8);
String host = urlBuilder.getHost();
System.out.println(host);
UrlQuery query = urlBuilder.getQuery();
Map<CharSequence, CharSequence> queryMap = query.getQueryMap();
for (Map.Entry<CharSequence, CharSequence> entry : queryMap.entrySet()) {
System.out.println(entry.getKey()+": "+entry.getValue());
}
输出
192.168.0.236
name: zhang san+lisi
age: 15
文章作者:Administrator
文章链接:http://localhost:8090//archives/httpprotocolnote
版权声明:本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0 许可协议,转载请注明出处!
评论